Last time was a custom PHP CMS with enough fancy features it even had dual-mode
HTML/XHTML rendering based on the
Accept-Content header. Look. It made sense at the time. Sort of. Shut up.
16(!) years later… it still mostly works, and it’s certainly not the worst
thing I’ve ever written, but I haven’t been a PHP guy in a long time, and it’s
time for a change.
So here I am with Gutenberg, a static site
generator written in my new favourite language, Rust. Whether or not I actually
do anything with it, I helped
fix bugs in
four different
projects in the process of
setting it up, and made a FreeBSD port, so it’s already paid off in my book.
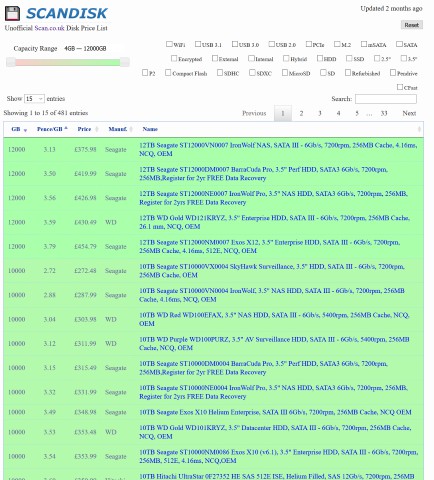
Sick of Scan.co.uk being a pain in the ass to browse for this
sort of thing, I wrote a scraper and frontend to browse available
storage devices and their prices.
Bloom filters are one of my favourite data structures,
in no small part because of just how simple they are.
I first encountered them when I worked at Newzbin, when we needed
a way of quickly determining if we’d seen a Usenet Message-ID before.
Their simplicity meant we were very quickly able to go from concept
to a stable general-purpose microservice which served us well for many
years.
One of the trickier aspects is knowing how to size one - typically
you know how many items and what sort of false-positive rate you can
stand, but how do you translate that to how many bits you need and
how many hash functions to use?
Well, bam. The latest iteration of my calculator can calculate almost
any valid set of parameters, and give you pretty graphs in real time,
while offering server-side fallback. I hope you find it useful.
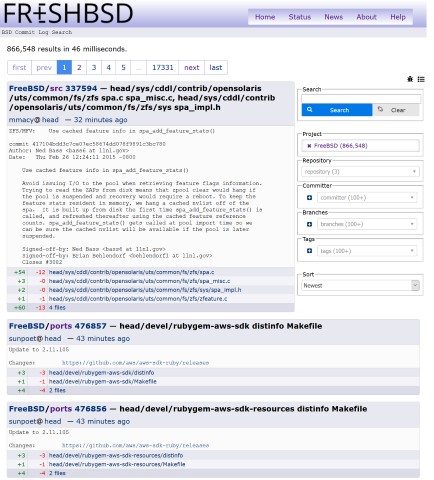
A search engine/viewer for source code commits, focused on projects of interest
to the BSD community.
Currently into its fourth rewrite, backed by Elasticsearch, PostgreSQL and
Redis, with the site itself running on JRuby and Roda, making use of
concurrent-ruby to parallelise data retrieval and inserts.
Previous versions have used Rails, Sinatra, Padrino, Solr, MySQL, and memcached.