mac_portacl(4) is a FreeBSD kernel security module providing an access control policy
for permitting specific users and groups to bind to ports that would otherwise be restricted
to the super-user.
portacl-rc is an rc script that makes configuring it easier and safer.
IMSErious is a tiny Rust web service that makes up part of my email infrastructure.
It responds to Open-Exchange IMSE messages from the Dovecot email server by executing
commands. In my case, I use it to trigger fdm – a mail retrieval agent.
Where zpool-iostat provides IO statistics for accesses to the lower level components
that make up a ZFS filesystem — the devices that underpin it and the mirrored, striped,
and parity-combined virtual devices these are part of — ioztat does so for the filesystems
and virtual block devices layered on top.
checkrestart is a FreeBSD semi-workalike of the old
checkrestart program from debian-goodies —
it looks for running processes with open files to replaced binaries and
libraries, indicating they’ve not been restarted since a software update.
In the popular space simulation game, Elite Dangerous, one of the challenges
is determining how best to outfit your ship — if you’re going into combat,
choosing the right shield, with the right boosters and the right engineering
can be the difference between life or death.
So why not sap the fun out of it by using a computer to work out the best configuration
for us?
One of the more notable features that shipped with Windows 10 is a new filesystem
compression system based on the Windows Overlay Filesystem architecture, originally
developed for transparent handling of disk images.
It’s intended for use in applications, in particular the base OS (in a feature
referred to as CompactOS), but sadly this is only exposed to users via a command
line program — compact.exe — and most users fail to take advantage of it.
tarssh is an SSH tarpit – a server that trickles an endlessly repeating introductory
banner to clients for as long as it remains connected, in order to expend the resources
of attackers.
It’s based on the same concept as Chris Wellons’ Endlessh, a similar service written in C.
cw is a fast Rust reimplementation of the classic Unix wc command, featuring
fast paths for most common modes of operation, including SIMD-accelerated line
and UTF-8 codepoint counting via the
bytecount crate (closing issue
#41 there in the process).
It also supports multithreading, because of course it does.
Even in single-threaded mode it is almost always much faster than either FreeBSD
or GNU wc implementations.
Yet another Ruby bloom filter,
and a new bit array implementation, including a speedy JRuby-specific version.
This was extracted from an experiment in leaked password list processing,
before I moved on to Golomb Compressed Sets, and might be worth extracting
into a proper gem at some point.
A small Ruby script for helping deal with cruft on
pkgng-based systems like FreeBSD.
Perhaps most interesting is the implementation of
checkrestart, a feature similar to the Debian-goodies
program of the same name, which can find running processes
which may need restarting following an upgrade.
# pkg-cruft checkrestart
[MISSING EXECUTABLE] (tmux-2.7)? running as 17319 (tmux)
[MISSING EXECUTABLE] (zsh-5.5.1)? running as 20115 (zsh)
[MISSING EXECUTABLE] (weechat-2.2)? running as 36747 (weechat)
/usr/local/bin/mosh-server (mosh-1.3.2_4) running as 53815 (mosh-server)
mkpass is a simple command-line random password generator written in Rust,
with built-in dictionaries to keep run-time dependencies to an absolute minimum.
rtss annotates its output with relative durations between consecutive lines
and since program start.
Inspired by Kevin Burke’s Golang tss,
I thought it would be a fun exercise and a nice bit of Rust practice to
implement something similar.
I’m fairly pleased with the result - it’s considerably faster, running at hundreds
of MB per second in my tests - and somewhat more featureful, including pty support,
allowing it to work similarly to expect’s unbuffer command.
Similar to Bloom Filters, Golomb Compressed sets allow for space-efficient
probablistic storage of sets. In other words, you can ask a GCS if it’s seen
an object, and retrieve either “absolutely not” or “probably not” in response.
gcstool was my first Rust project, developed primarily to play about with
the haveibeenpwned.compwned-passwords-2.0.txt database. It can store all
half a billion items with a false-positive rate of 1-in-50 million in just 1.6GB,
importing them in just a few minutes, though with fairly high memory requirements.
run-one is basically a thin wrapper around lockf(1), or on Linux flock(1):
-% lockf /var/tmp/sleep-5.lock sleep 5
# <runs sleep 5 under the named lock>
-% run-one sleep 5
# <runs sleep 5 under a lock named by a SHA256 of its arguments>
FastFind is a drop-in replacement for the standard library Find package.
I wrote this for FreshBSD, to speed up scanning CVS repositories - walking
300,000 files takes a while, especially with an API that basically forces you
to File.stat twice for each one.
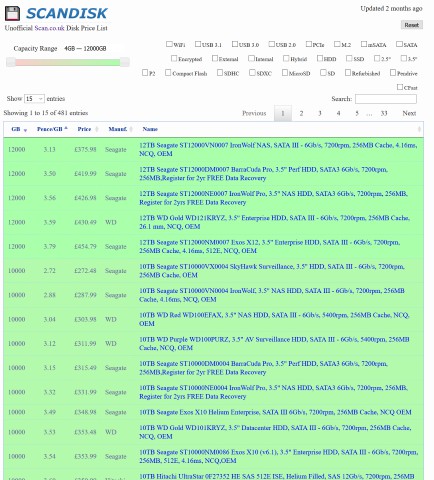
Sick of Scan.co.uk being a pain in the ass to browse for this
sort of thing, I wrote a scraper and frontend to browse available
storage devices and their prices.
Bloom filters are one of my favourite data structures,
in no small part because of just how simple they are.
I first encountered them when I worked at Newzbin, when we needed
a way of quickly determining if we’d seen a Usenet Message-ID before.
Their simplicity meant we were very quickly able to go from concept
to a stable general-purpose microservice which served us well for many
years.
One of the trickier aspects is knowing how to size one - typically
you know how many items and what sort of false-positive rate you can
stand, but how do you translate that to how many bits you need and
how many hash functions to use?
Well, bam. The latest iteration of my calculator can calculate almost
any valid set of parameters, and give you pretty graphs in real time,
while offering server-side fallback. I hope you find it useful.
pqsort is the sorting library I wrote for Newzbin’s custom search engine - it’s
a lightly modified quicksort capable of partitioning and sorting only part of
a list.
Quicksort lends itself very well to this kind of use due to how it works - it
naturally partitions the list based on a pivot, and so it’s trivial to simply
ignore any pivot side which cannot contain the desired results.
A foray into lower-level code, bashing PCI registers and using a bit of custom
assembler, k8temp offers a command line interface to the thermal sensors on
AMD’s old K8 CPUs.
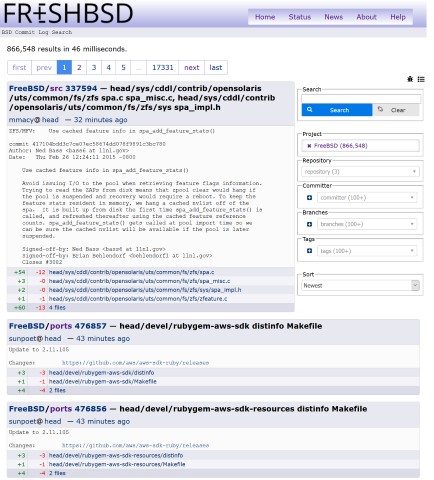
A search engine/viewer for source code commits, focused on projects of interest
to the BSD community.
Currently into its fourth rewrite, backed by Elasticsearch, PostgreSQL and
Redis, with the site itself running on JRuby and Roda, making use of
concurrent-ruby to parallelise data retrieval and inserts.
Previous versions have used Rails, Sinatra, Padrino, Solr, MySQL, and memcached.
Many, many years ago, I wrote this for unclear reasons. I don’t think I actually
used it for anything. It implements the PHP serialize() and unserialize()
functions in Ruby, allowing you to read/write PHP sessions and otherwise share
objects between the two.
Now the various forks of it have nearly half a million downloads between
them. php-serialize is the “official” version, with nearly half of those.
The exact incept date is uncertain, the earliest mention of it a quick search finds
is ruby-talk:73669, 2003-06-16.
 Continue Reading
Continue Reading